While popular knowledge graphs such as DBpedia and YAGO are built from Wikipedia, Wikifarms like Fandom contain Wikis for specific topics, which are often complementary to the information contained in Wikipedia, and thus DBpedia and YAGO. Extracting these Wikis with the DBpedia extraction framework is possible, but results in many isolated knowledge graphs. In this paper, we show how to create one consolidated knowledge graph, called DBkWik, from thousands of Wikis. We perform entity resolution and schema matching, and show that the resulting large-scale knowledge graph is complementary to DBpedia.
Linked Open Data Endpoint
We provide a Linked Data endpoint using derefencable URIs. To browse the LOD enpoint, use, e.g., the concept Harry Potter.
SPARQL Endpoint
The SPARQL Enpoint is available at /sparql.
-
The following query retrieves instances with a specific label: (Open results in browser):
SELECT * WHERE{ ?s rdfs:label "Harry Potter"@en; ?p ?o. } -
Find the house of Harry Potter: (Open results in browser):
SELECT ?p ?o WHERE{ ?harry_potter rdfs:label "Harry Potter"@en. ?house rdfs:label "House"@en. ?harry_potter ?house ?harry_potter_house. ?harry_potter_house ?p ?o. } -
Show all episodes: (Open results in browser):
SELECT * { ?s a <http://dbkwik.webdatacommons.org/resource/KcNVnWOfCI-Oo7mEf-Ol4g==>; rdfs:label ?label. } -
Show all resources with type song: (Open results in browser):
SELECT ?s ?label { ?s a ?clazz; rdfs:label ?label. ?clazz rdfs:label "Song"@en. }
Dataset Description
The VOID file is located at http://dbkwik.webdatacommons.org/.well-known/void The dataset is also described at datahub with the name dbkwik. The prefix is also dbkwik.
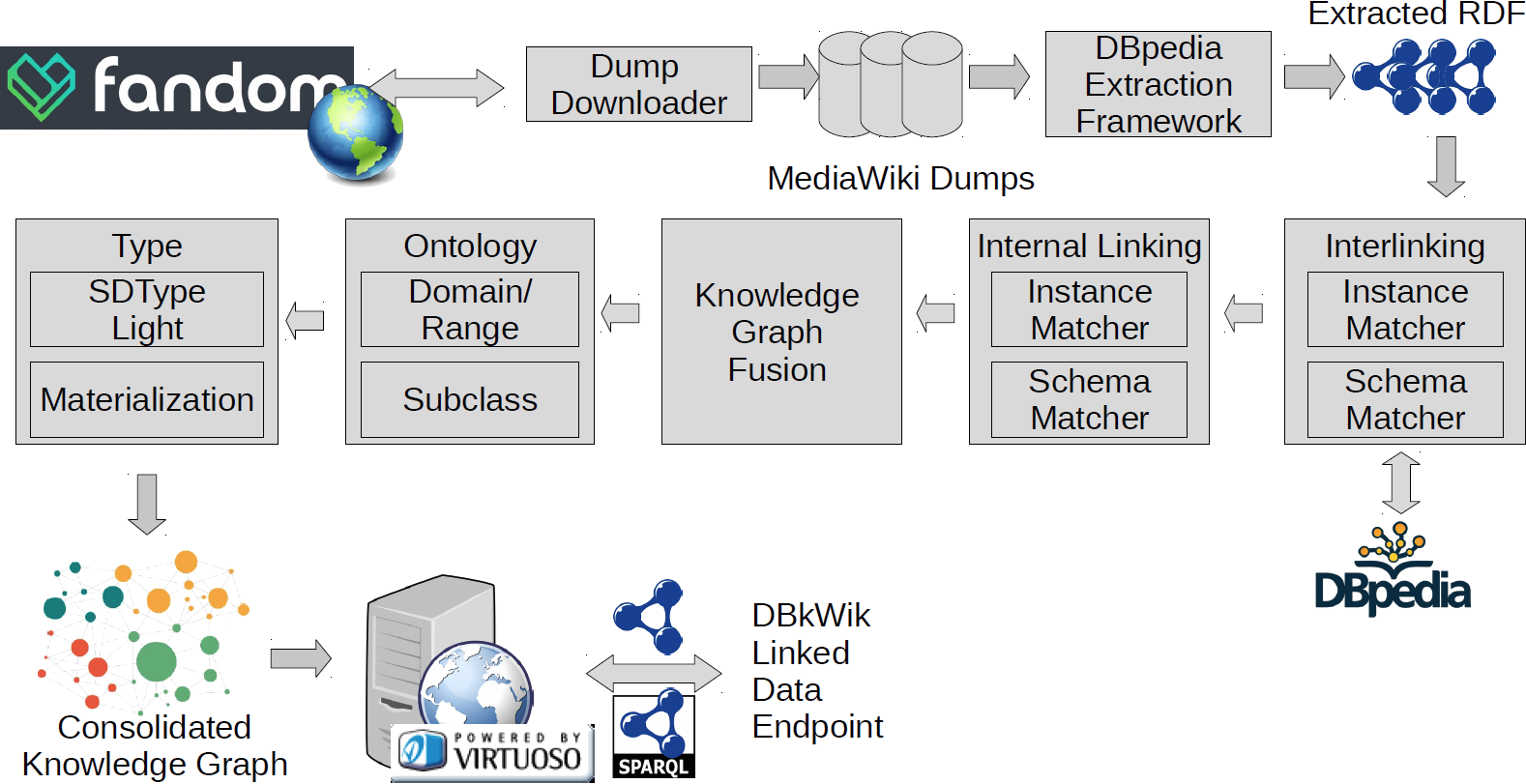
The whole approach is shown below:
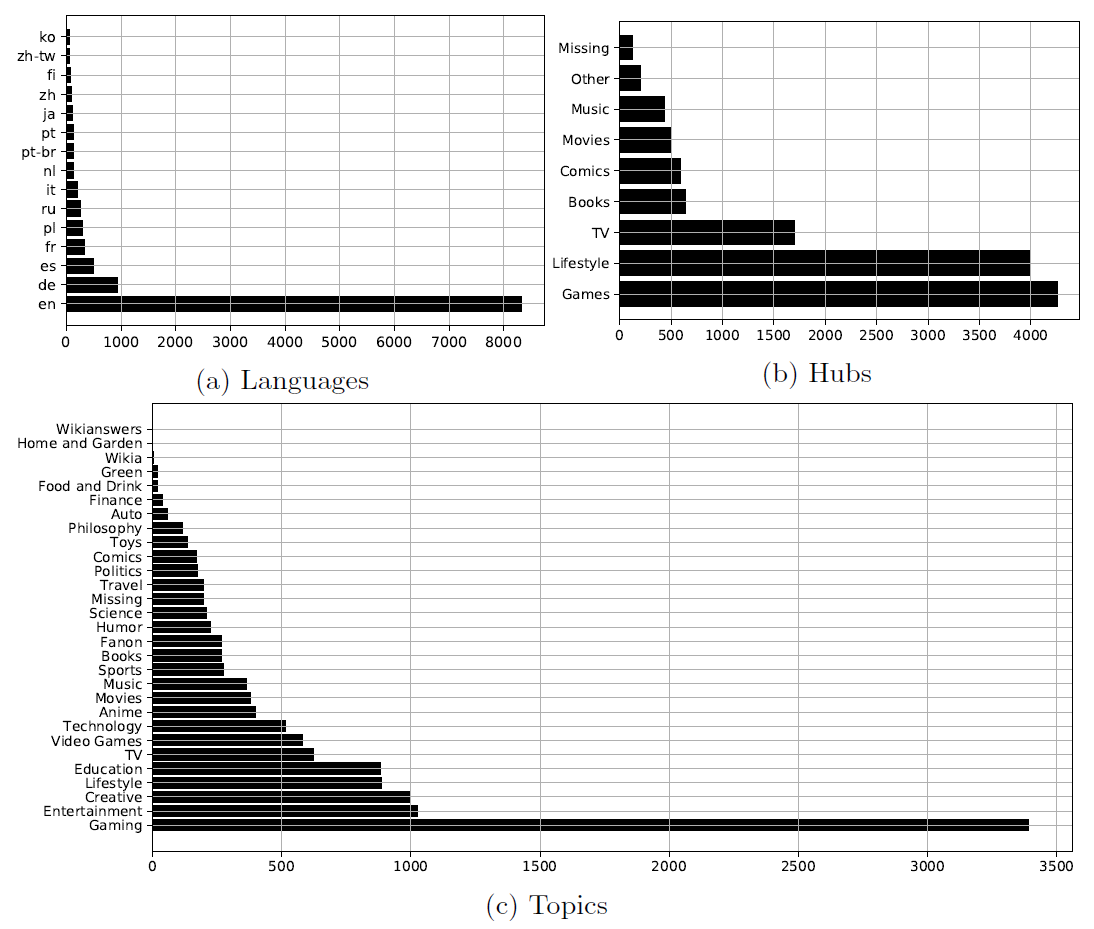
The distribution of topics, hubs and languages of all wikis contained in this endpoint:
Dataset Statistics
The following table shows some basic statistics of the overall dataset:
| Instances | 11,163,719 |
| Typed instances | 1,372,971 |
| Axioms | 91,526,001 |
| Avg. indegree | 0.703 |
| Avg. outdegree | 8.169 |
| Classes | 12,029 |
| Properties | 128,566 |
Data Dumps
The following versions of the dataset are available:
| Date | Version | No. of input wikis | Release notes | ||
|---|---|---|---|---|---|
| 2022-10-06 | 2.0 | 40,000 | More Wikis integrated with incremental merge based approach | download | |
| 2018-04-01 | 1.1 | 12,840 | Introduces data fusion and lightweight schema induction | download | |
| 2018-01-31 | 1.0 | 12,840 | First version of the dataset | download | |
| 2017-07-21 | - | 248 | Proof of Concept | download |
Crowdsourcing results
We have crowdsourced two gold standards, one for the mapping between DBkWik and DBpedia, one for matching instances inside DBkWik.
Survey template for interwiki mapping (preview - source) And the resulting gold standards (in alignment format - see alignment api):
Code Repository
The code repository with all results is hosted at github:
- sven-h/dbkwik for the fusion and the gold standards
- WikiaTeamProject/ExtractionFromWikia for the extraction of the first dumps
Citing DBkWik
- Sven Hertling and Heiko Paulheim. DBkWik++- Multi Source Matching of Knowledge Graphs. In Knowledge Graphs and Semantic Web (KGSWC), Madrid, Spain, volume 1686, pages 1-15. Springer, 2022. Best Paper. [pdf]
- Sven Hertling and Heiko Paulheim. DBkWik: extracting and integrating knowledge from thousands of Wikis. Knowledge and Information Systems (KAIS), 62(6):2169-2190, 2020. [Springer Link]
- Sven Hertling and Heiko Paulheim. DBkWik: A Consolidated Knowledge Graph from Thousands of Wikis. In International Conference on Big Knowledge (ICBK), Singapore, pages 17-24. IEEE, 2018.[pdf]
- Alexandra Hofmann, Samresh Perchani, Jan Portisch, Sven Hertling, and Heiko Paulheim. DBkWik: Towards Knowledge Graph Creation from Thousands of Wikis. International Semantic Web Conference (Posters & Demos) 2017. [pdf]
License
This dataset uses material from multiple wikis at FANDOM and is licensed under the Creative Commons Attribution-Share Alike License. See also the license page at Fandom.